Here you'll find some tools that I developed and which can be accessed online.
Complex Word Identification with Graded Lexical Databases
Web-based tools for identifying difficult words in a text with a graded lexical database
Complex Word Identification with Graded Lexical Databases
As part of my Master’s and Ph.D. in NLP, I developed several web-based tools to automatically identify difficult words in a text with a graded lexical database.
My very first paper (Tack et al. 2016-05-23/2016-05-28) introduced a simple, lexicon-based tool that could automatically identify difficult words in a given text based on a graded lexical database. This database had previously been extracted from a corpus of reading materials labeled by experts based on a scale of grade levels (e.g., K-12, CEFR, …). The tool only required a couple of parameters:
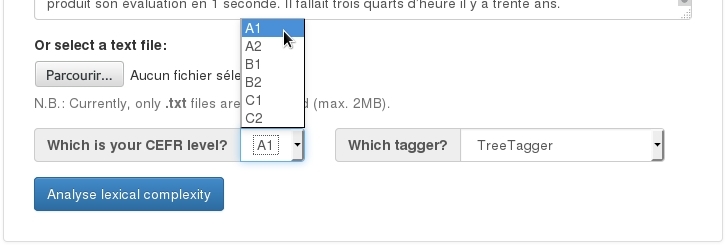
- A targeted grade level. This is the specific grade level (e.g., 1st grade, A1, …) for which the tool produces an analysis of lexical complexity.
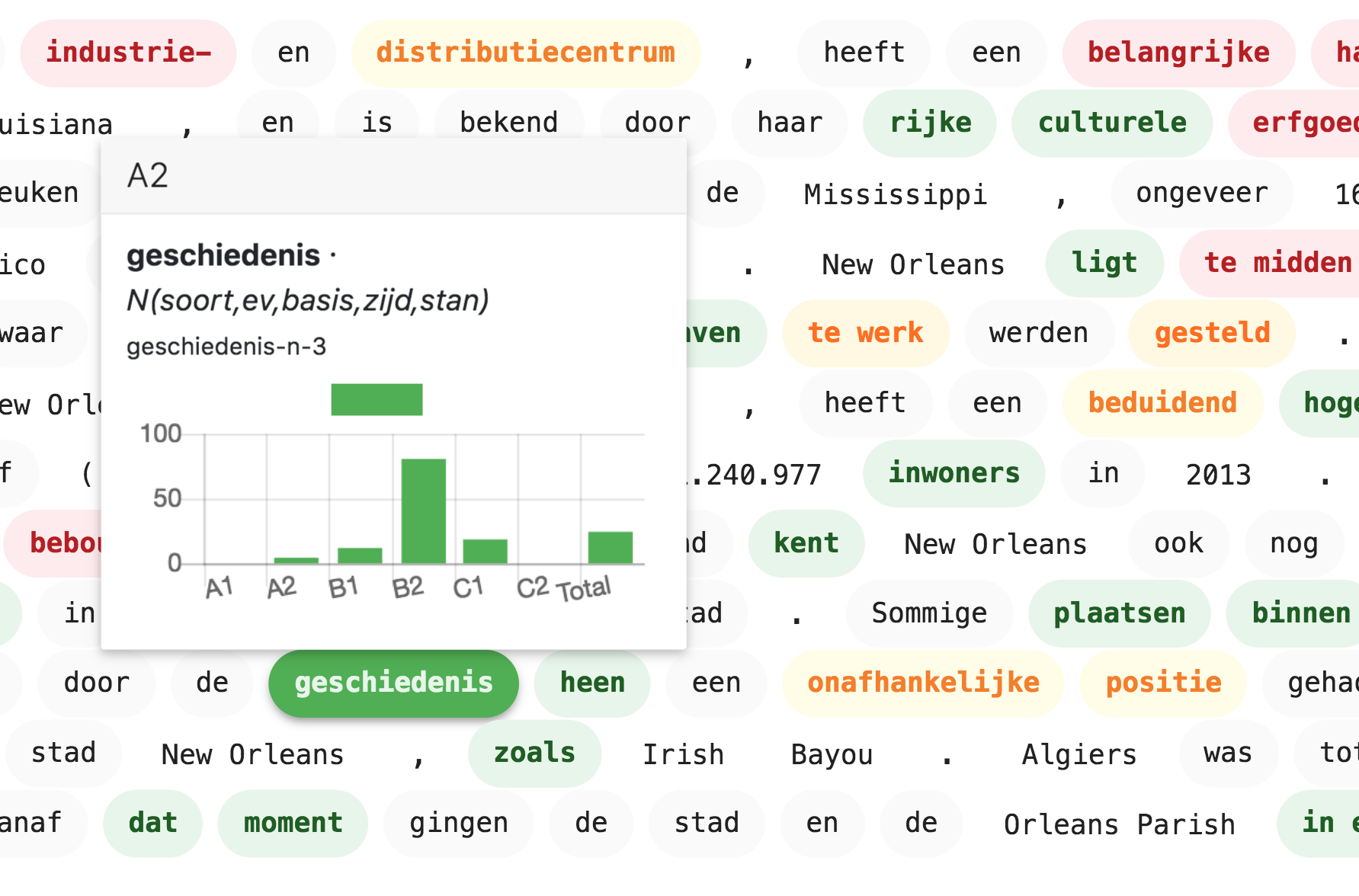
- A graded lexical database. This is a tabular database with each row containing a lexical entry (identified by a lemma, a part of speech, and, possibly, a meaning) and with each column indicating how frequently the entry occurs in reading materials at a specific grade level.
- A lemmatizer, a part-of-speech tagger, and a word-sense disambiguator. These are systems that automatically produce, for each word in the text, the entry (lemma, part of speech, and meaning) as used in the lexical database. Initially, I only used a lemmatizer and a part-of-speech tagger. In a later paper, I added the use of word-sense disambiguation (Tack et al. 2018).
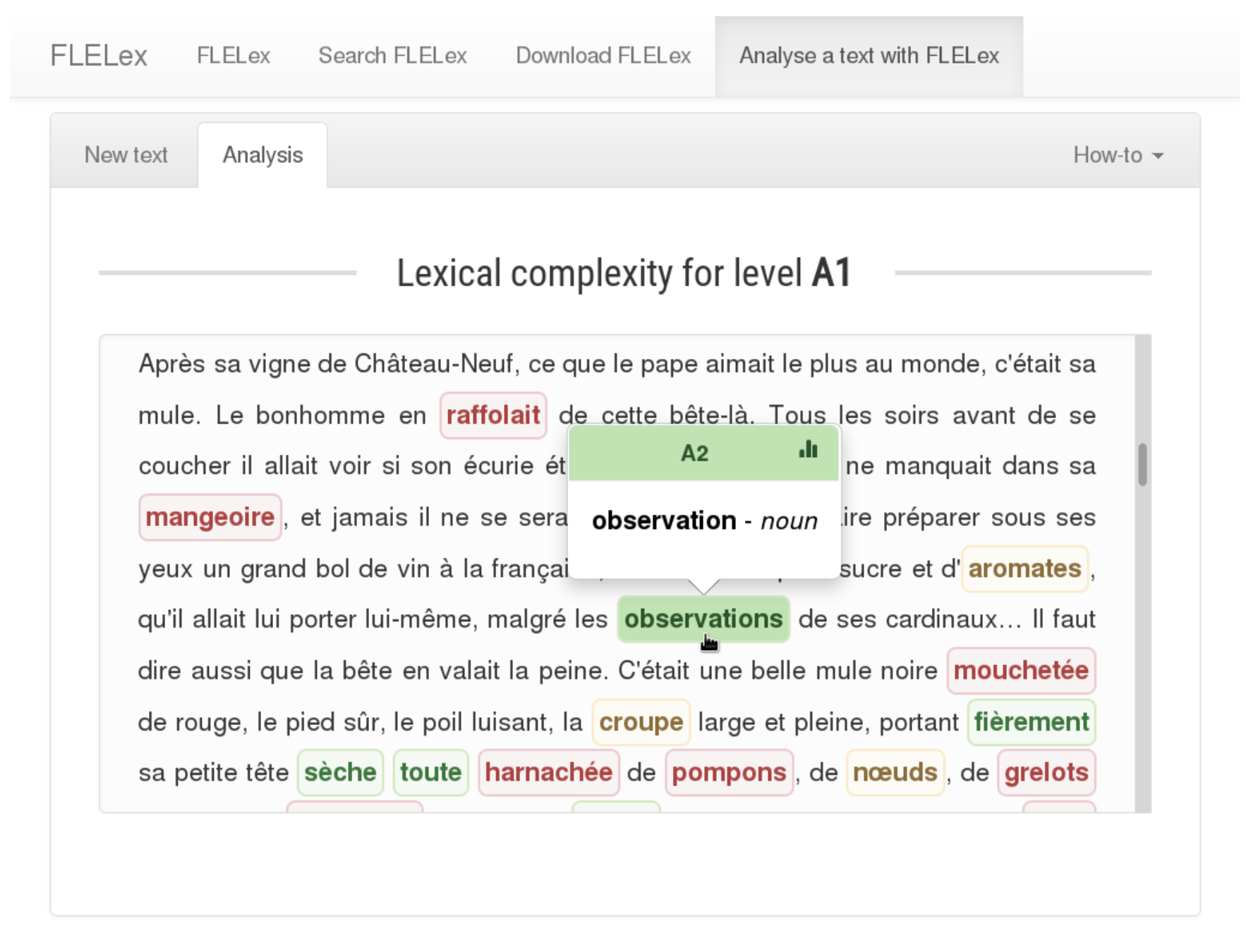
The tool used a two-step heuristic to identify difficult words in a text.
- A word is highlighted (labeled as difficult or complex) if its entry does not occur in the graded lexical database. In other words, the word is difficult because it does not occur in reading materials intended for any of the grade levels.
- A word is highlighted (labeled as difficult or complex) if its entry only occurs at grade levels that are higher than the targeted grade level. This can be simplified by considering only the first level at which the entry appears. If this first grade level is higher than the targeted grade level, then we can assume that any other level at which the entry occurs will also be higher than the targeted level.
Although I initially developed these web-based tools for French and Dutch (which was the focus of my studies), I designed the infrastructure so that it could be used for multiple languages. This multilingual infrastructure then facilitated the integration of my two tools for French and Dutch with the tools that were developed later for other languages in the CEFRLex project. All available tools can be found here: https://cental.uclouvain.be/cefrlex/analyse/.
Lexical Complexity Analysis for French
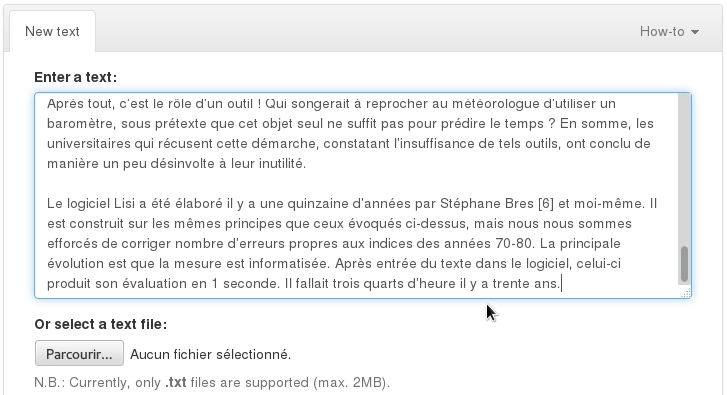
I developed a first version of this tool in the summer of 2014. At the time, I was a research intern at the Computer Science Laboratory for Mechanics and Engineering Sciences (LIMSI-CNRS, Université Paris-Sud, France), supervised by Anne-Laure Ligozat. During my internship, I worked on the automated analysis of lexical complexity for French elementary school children (with the MANULEX database) and for French as a foreign language learners (with the FLELex database). I compared the tool’s output with manual lexical simplifications in Vikidia, a simplified Wikipedia for children. I published and presented the results at the International Conference on Language Resources and Evaluation (Tack et al. 2016-05-23/2016-05-28). After my internship, I developed a web interface for the tool, as illustrated in the images below.
Lexical Complexity Analysis for Dutch
During my Ph.D. at UCLouvain and KU Leuven, I introduced a new graded lexical database for Dutch (Tack et al. 2017) and developed a new version of the tool. This new version was designed as an Angular Material Design UI connected to an object-oriented RESTful backend developed in the Django framework. Although the system was specifically developed for the first publication of NT2Lex (Tack et al. 2018), its database architecture was independent of the tabular database format. As a result, future resources developed for other languages could be easily added to the system.
References
- Tack, Anaïs, Thomas François, Piet Desmet & Cédrick Fairon. 2018. NT2Lex: A CEFR-Graded Lexical Resource for Dutch as a Foreign Language Linked to Open Dutch WordNet. In Joel Tetreault, Jill Burstein, Ekaterina Kochmar, Claudia Leacock & Helen Yannakoudakis (eds.), Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications, vol. 13, 137–146. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-0514 (1 June, 2018).
- Tack, Anaïs, Thomas François, Piet Desmet & Cédrick Fairon. 2017. Introducing NT2Lex: A Machine-readable CEFR-graded Lexical Resource for Dutch as a Foreign Language. Presentation. Leuven, Belgium.
- Tack, Anaïs, Thomas François, Anne-Laure Ligozat & Cédrick Fairon. 2016-05-23/2016-05-28. Evaluating Lexical Simplification and Vocabulary Knowledge for Learners of French: Possibilities of Using the FLELex Resource. In Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, Sara Goggi, Marko Grobelnik, Bente Maegaard, Joseph Mariani, et al. (eds.), Proceedings of the Tenth International Conference on Language Resources and Evaluation, vol. 10, 230–236. Portorož, Slovenia: European Language Resources Association.

Search in Graded Lexical Databases
Web-based tools for searching and comparing lexical entries in graded lexical databases
ingi/inginious-c-unitex-nlp
Docker container to use the Unitex/GramLab NLP engine on the INGInious automated grading platform